مطلب ۸ (قسمت دوم) :بررسی MapReduce در مقیاس گسترده با استفاده از هدوپ
با مطالعه و بررسی قسمت اول این مطلب، حال واضح است که چرا سایز مناسب یک Split بهتر است به اندازه سایز یک بلاک از HDFS باشد زیرا این اندازه بیشترین مقدار داده ورودی است که می توان مطمئن بود روی یک نود بصورت کامل ذخیره می شود. اگر یک Split بین دو Block پخش شود، احتمال اینکه که یک نود به تنهایی هر دو بلاک را در خود نگهداری نماید زیاد نخواهد بود، بنابراین در این حالت برخی از Split ها مجبوراند به منظور رسیدن به نودی که اجرای Map Task را برعهده دارد روی شبکه منتقل شوند، که البته روشن است کیفیت این نوع پردازش نسبت به حالتی که داده بصورت محلی وجود دارد متفاوت خواهد بود.
Map Task ها خروجی خود را بروی دیسک محلی ذخیره می نمایند، شاید این سوال مطرح شود که چرا از HDFS به منظور این کار استفاده نمی شود؟ خروجی Map به عنوان یک خروجی میانی شناخته می شود: این داده توسط Reduce Task ها مورد پردازش قرار می گیرد تا بر همین اساس خروجی نهایی به وجود آید، و هر گاه اجرای یک Job به اتمام برسد خروجی Map دیگر مورد استفاده قرار نمی گیرد. بنابراین ذخیره سازی آن بروی HDFS (با در نظر گرفتن مکانیزم تکثیر بلاک ها به منظور جلوگیری از Data Loss) یک کار بیهوده خواهد بود. اگر نود اجرا کننده یک Map Task قبل از اینکه بتواند خروجی خود را به یک Reduce Task برساند با شکست مواجه شود، هدوپ بصورت خودکار آن Map Task را بروی نود دیگری به منظور تولید مجدد خروجی Map دوباره به اجرا در خواهد آورد.
Reduce Task ها از مزایای محلی سازی داده بهره نمی برند زیرا ورودی یک Reduce Task بصورت نرمال خروجی بدست آمده از همه Mapper ها خواهد بود. در مثال حاضر، یک Reduce Task وجود دارد که توسط تعدادی Map Task تغذیه می شود. از این رو، خروجی های Map مرتب سازی شده مجبوراند برای رسیدن به نودی که اجرای Reduce Task مربوطه را برعهده دارد روی شبکه منتقل شوند، جایی که آنها با یکدیگر ادغام شده و بعد از آن به تابع Reduce نوشته شده توسط برنامه نویس فرستاده می شوند. خروجی بدست آمده از Reduce بصورت نرمال به منظور اطمینان بیشتر بروی HDFS ذخیره می شود. همانطوری که در مطالب بعدی خواهیم گفت، برای هر Block از HDFS مربوط به خروجی Reduce، اولین کپی روی نود محلی قرار می گیرد، و الباقی روی نودهای خارج از Rack نگهداری می شوند. درنتیجه نوشتن خروجی Reduce باعث استفاده پهنای باند شبکه خواهد شد، که البته میزان آن تحت کنترل هدوپ خواهد بود.
تمام جریان داده با استفاده از یک Reduce Task در زیر به تصویر کشیده شده است. قسمت های نقطه چین بیانگر نودها، خطهای جهت دار روشن بیانگر انتقال داده روی یک نود، و خطهای جهت دار تیره بیانگر انتقال داده بین نودها می باشند.

MapReduce data flow with a single reduce
اندازه ورودی هیچگونه تاثیری بروی تعداد Reduce Task ها ندارد و آنها بصورت مستقل تعیین می شوند. در مطالب آتی در مورد آن بیشتر صحبت خواهیم کرد.
وقتی چندین Reducer وجود داشته باشند، Map Task ها خروجی خود را پارتیشن بندی می کنند، هر کدام از آنها یک پارتیشن برای هر یک از Reduce Task ها ایجاد می نماید. در این حالت، تعداد زیادی Key (و Value های متناظر با آنها) در هر پارتیشن می تواند وجود داشته باشد، اما تمامی رکوردهای مربوط به یک Key تنها در یک پارتیشن قرار دارند. عمل پارتیشن سازی می تواند توسط برنامه نویس کنترل گردد، اما بصورت نرمال یک پارتیشن کننده قوی بصورت پیش فرض وجود دارد که Key ها را توسط یک Hash Function دسته بندی می نماید.
جریان داده برای حالت عمومی استفاده از چندین Reduce Task در زیر به تصویر کشیده شده است.با در نظر گرفتن اینکه هر Reduce Task توسط تعدادی Map Task تغذیه می شود، در این شکل به خوبی مشخص است چرا جریان داده بین Map Task ها و Reduce Task ها در اصطلاح به تلفیق سازی (Shuffle) معروف می باشد. البته مکانزیم تلفیق سازی پیچیده تر از آن است که در این شکل آمده، و در صورت تنظیم صحیح می تواند تاثیری زیادی بروی زمان اجرای یک Job داشته باشد.

MapReduce data flow with multiple reduce tasks
در پایان، این امکان وجود دارد که یک Job بدون داشتن Reduce Task تعریف و اجرا گردد. این درحالی است که نیاز به تلفیق سازی وجود ندارد و نتیجه کلی اجرا تنها با انجام پردازش موازی بدست می آید. در تصویر بعدی حالتی بیان می شود که تنها انتقال داده زمانی صورت می پذیرد که Map Task ها خروجی خود را روی HDFS می نویسند.
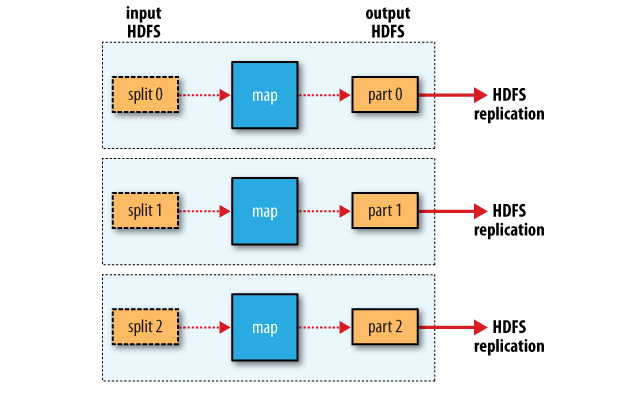
MapReduce data flow with no reduce tasks
Hadoop: The Definitive Guide by Tom White
