مطلب ۵ : هدوپ و اکوسیستم آن
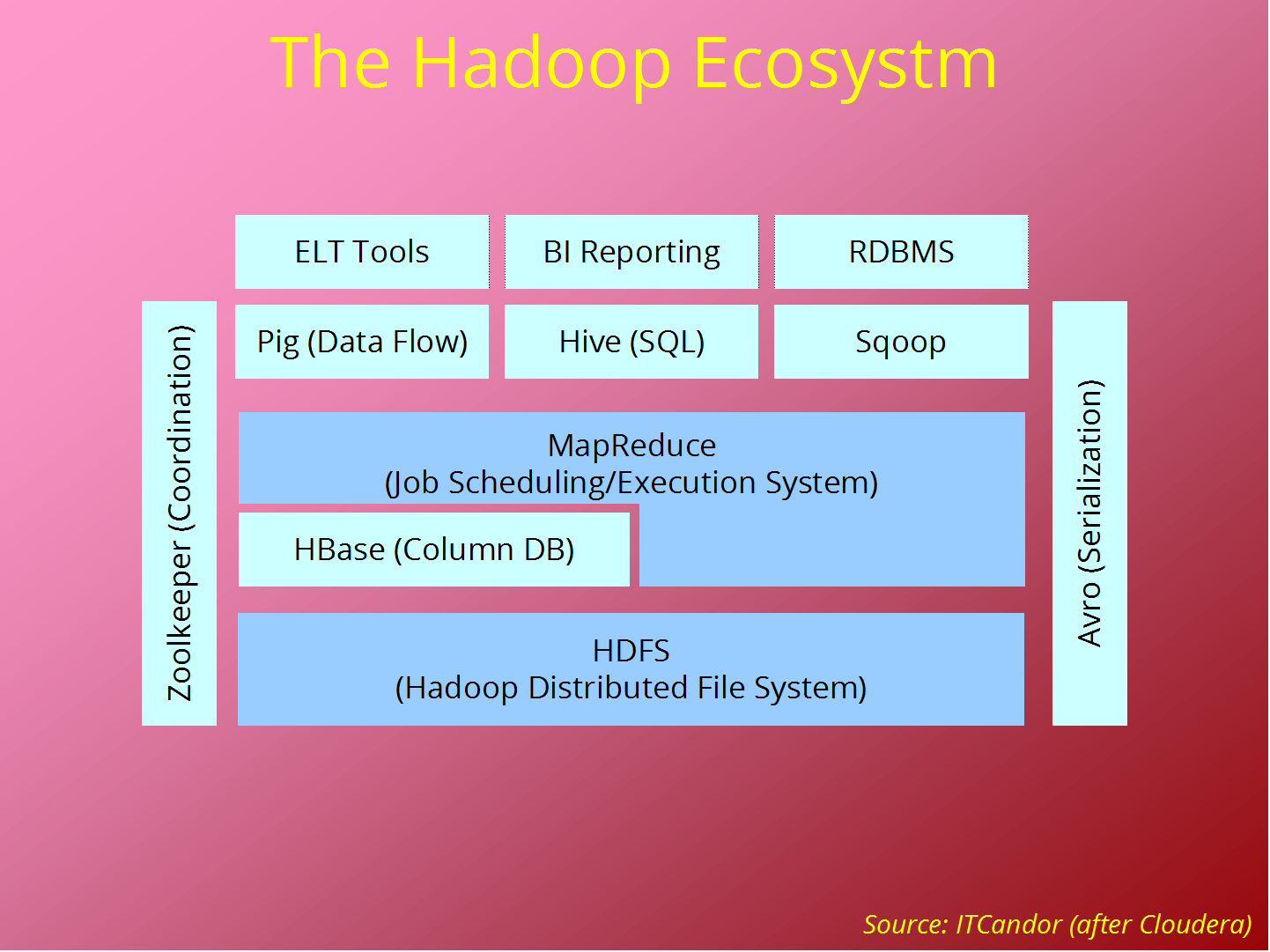
از آنجایی که هدوپ شهرت خود را به واسطه وجود قسمت های اصلی اش یعنی فایل سیستم توزیع شده (HDFS) و MapReduce بدست آورده است، باعث ایجاد الگویی در فضای محاسبات توزیع شده و پردازش داده حجیم شده است، که به واسطه آن مجموعه ای از پروژه های مرتبط به منظور هرچه کاملتر شدن هدوپ شکل گرفته است. بیشتر این پروژه توسط Apache Software Foundation حمایت می شوند.
در ادامه برخی از آنها به اختصار توضیح داده شده اند:
Common
مجموعه ای از مولفه ها و سرویس ها برای فایل سیستم های توزیع شده و مفاهیم عمومی I/O نظیر Serialization،
(Java Remote Procedure Call (RPC می باشد.
Avro
یک سیستم Serialization به منظور هر چه کارا تر شدن تبادل داده بین زبان های برنامه نویسی(RPC) می باشد.
MapReduce
مدلی است برای پردازش داده توزیع شده و همچنین محیطی برای اجرا که در آن کلاسترهایی از ماشین ها وجود دارند.
HDFS
یک فایل سیستم توزیع شده با قابلیت اجرا بروی کلاسترهایی از ماشین ها می باشد.
Pig
زبانی است برای مدل سازی جریان داده و همچنین محیطی برای مشاهده مجموعه های داده حجیم می باشد. Pig بروی کلاسترهای HDFS و MapReduce اجرا می شود.
Hive
یک انبار داده توزیع شده می باشد. Hive داده ذخیره شده در HDFS را مدیریت نموده و زبانی را برای ایجاد Query بر مبنی SQL (که در زمان اجرا تبدیل به تعدادی کار در MapReduce می شود) برای کار با داده فراهم کرده است.
HBase
یک پایگاده داده توزیع شده ای است که طراحی آن براساس سطر و ستون می باشد. HBase از HDFS به عنوان مخزن داده اصلی خود استفاده می نماید، و همچنین هر دونوع محاسبات که با استفاده از MapReduce و Query های موردی (واکشی تصادفی) انجام می شود را پوشش می دهد.
ZooKeeper
یک سرویس هماهنگ سازی توزیع شده ای است که همواره در دسترس می باشد. برای مثال، هماهنگی استفاده از Lock ها که در ساخت برنامه های توزیع شده بسیار کاربرد دارد.
Sqoop
ابزاری است کارا که برای انتقال داده بین پایگاه داده رابطه ای و HDFS مورد استفاده قرار می گیرد.
Hadoop: The Definitive Guide by Tom White

 رسول مسعودی
رسول مسعودی